AI-Powered Knowledge Retrieval System
- Postgres
- Node.js
Lucas Ferguson
—Feb 03, 2025
AI-Powered Search for My Notes
Introduction
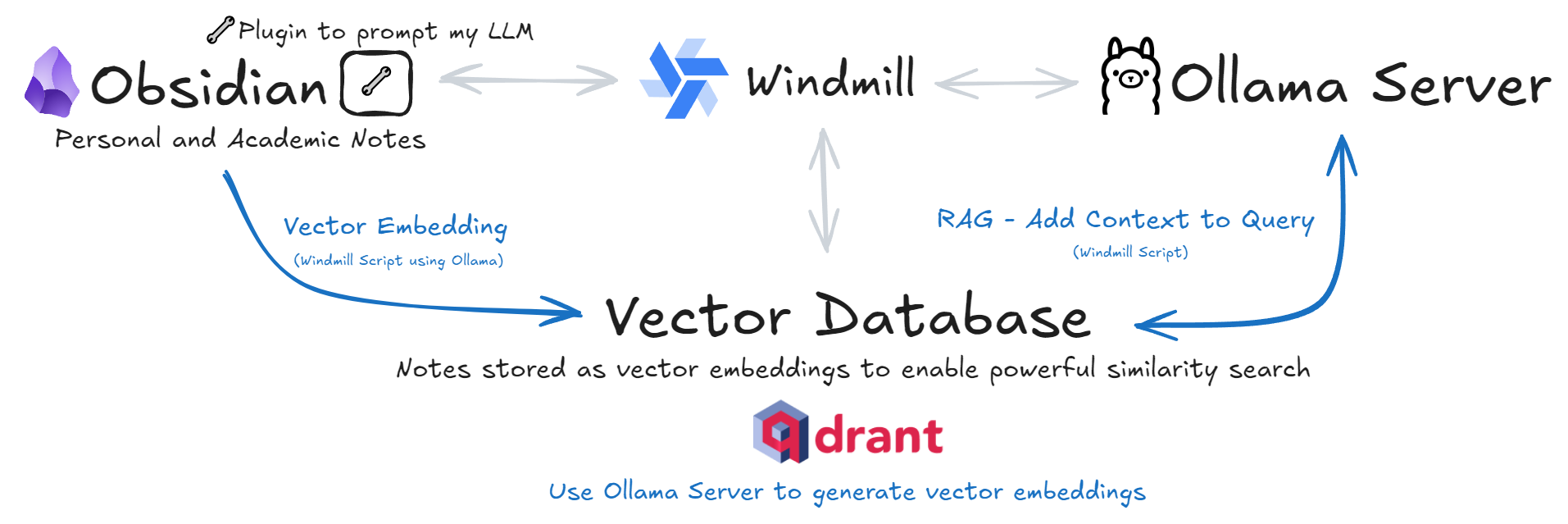
Searching all my notes efficiently became a challenge as my collection in Obsidian grew beyond 2,000 text files, PDFs, and images. Keyword searches were not enough, so I built an AI-powered knowledge retrieval system using all open source and self hosted tools including Qdrant for my Vector Database, Windmill as a platform to run python scripts, and Ollama to generate vector embeddings. All of which run in my Home Lab which you can learn more about by clicking here.
The Knowledge Retrieval System Steps
1. Data Processing & Embeddings Python Script
- A Python script running on Windmill preprocess notes by recursively scanning all directories and adding the file paths to an array.
- Using Ollama's API it generates vector embeddings for each markdown note.
- These embeddings and the note contents are inserted to Qdrant which stores and indexes embeddings for similarity search.
2. Semantic Search Engine
- A Python script, also running on Windmill, performs semantic search by converting queries into embeddings and retrieving relevant notes from Qdrant.
- Due to the nature of LMM text embedding this approach retrieves conceptually related information beyond just keyword matching.
3. LLM Integration for Context
- The results of a Semantic Search for notes can be passed as context to an LLM running with **Ollama **to analyze retrieved notes and answer follow-up questions.
4. AI Agent for Context Retrieval
- The system autonomously fetches related notes if additional context is needed.
- Example: A query like “Who taught me about CNNs?” finds notes related to convolutional neural networks, which all contain the course they were taken in at the top of the note. From there, another semantic search for that course title will find a note containing the syllabus and therefore the professor's name.
Main steps of AI Agent
- Retrieve relevant notes using semantic search.
- Analyze results with LLMs for relavent information
- Repeat until requested information is found 🔁
- Output result to user
Tech Stack
- Python for scripting and integrating everything together.
- Windmill platform to run automated Python scripts
- Qdrant as a vector database
- Ollama API for embeddings.
- Obsidian as the note-taking platform.
- Proxmox hypervisor for my server.
- Ubuntu operating system hosting containers
- Docker running Ollama, Qdrant, and Windmill
Lessons & Future Improvements
What I Learned
- Generating vector embeddings requires far less resources than I originally thought.
- I should always use absolute paths as opposed to relative ones when making Linux Shell Scripts because I may want to run that script from multiple directories
Next Steps
- Improve support for images & PDFs.
- Improve retrieval accuracy with better ranking models.
- Automate YAML metadata extraction.
- Create a Plug-in that will allow me to use this system right inside of Obsidian
Conclusion
I’m excited to keep refining this system and exploring new ways to make information retrieval smarter!
🚀 Thank you for reading!